在线HTML源码任意内容提取BeautifulSoup版
规则编写
常见的写法说明:
name="div" 其中的name指的是标签名,比如标签div,a,img,h1,code,p,span等
如果单纯指定标签名,很可能提取到一些不是你需要的内容,那么就需要配合下面的属性值来更精确的匹配到需要的内容
attrs={"class":"btn","style":"margin-top:30px"} 其中的attrs指的是标签属性,比如常见属性class,style,id,type,placeholder,title,alt或者其他自定义属性等等
name="span",attrs={"id":regex("abc\d{3}")} 这种格式是指定查找span标签,匹配这个标签中id属性值包含abc,且abc后面含有三位数字的内容, 其中字符串中的regex未固定格式,把正则内容写到()里即可
text 指的是输出为文本格式
你只要记住name是指定标签,attrs是指定属性值,attrs的格式其实是个字典,然后按示例格式写,就可以啦,就这么简单,习惯之后,提取任何html内容,犹如探囊取物!
格式是按照BeautifulSoup的find或者find_all模式写的,所以会用这个工具,基本上BeautifulSoup你也会了,反过来,你会BeautifulSoup,用这个工具应该是一看就会
建议使用火狐或者谷歌浏览器的查看元素来分析html源码,进行规则填写,相当方便和简单
在线HTML源码任意内容提取BeautifulSoup版工具介绍
正则表达式是个好东西,如果你不会,那么也没有问题,通过填写简单的标签名和属性的组合,即可提取到你想提取的html网页中的任意内容,怎么样,酷不酷?
本工具直接采用BeautifulSoup库,通过对用户输入的标签和属性来进行内容提取,对于提取到的内容暂时默认采用回车进行拼接,后期会添加自定义
之所以写这么一个工具,有时候需要提取一些链接或者html标签或者特定属性的内容,虽然本地写脚本也能很快实现,但终究是感觉麻烦!
目前本工具只是一个雏形,本来想添加更多的功能进去,想把html搞成目录树显示,然后供用户图形化提取想要的内容,研究了一下js的一个目录书库,css界面我一直弄不漂亮
想到一个折中的办法,现在很多浏览器都支持查看html元素了,其实那个就类似目录树了,我就无需再造轮子了
暂时就先凑合着写出来吧,慢慢完善
使用建议
html源码对于不同的程序员,各种各样的奇葩代码,对于不标准的html,可能会提取到意想不到的结果,所以请尽量规范您输入的代码
为了防止html源码内其他代码块的干扰,我的建议是使用谷歌浏览器或者火狐浏览器的查看元素,只输入您需要提取内容的html代码块,找到您需要提取的内容的标志,比如属性,标签名,然后在本工具输入即可
比如我想提取http://whatweb.bugscaner.com/这个网站主页的支持识别的cms,那么你可以把html如下图这样提取,粘贴到输入框
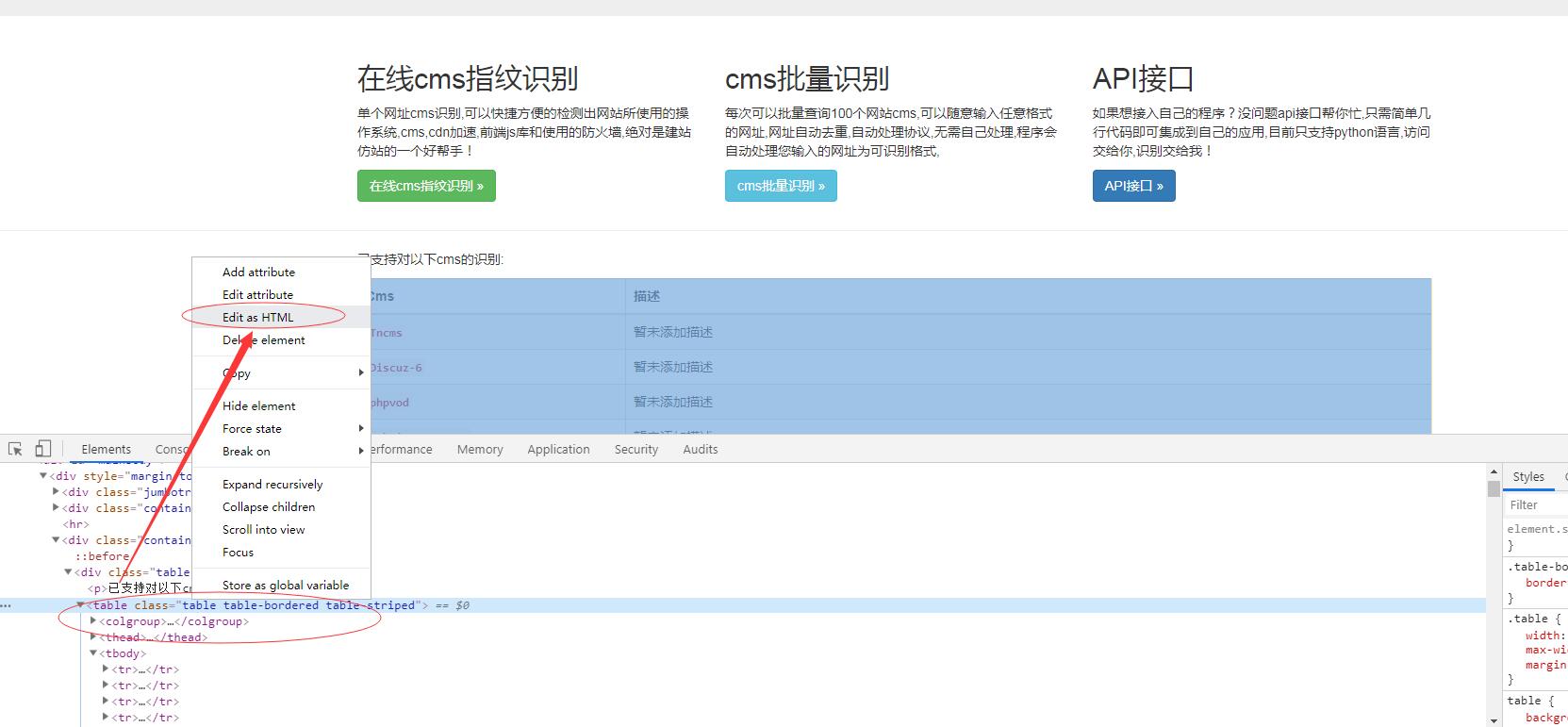
<th scope="row"><code>Django</code></th>
那么你只需要输入name="code",即可遍历html源码提取到想要的内容,你还可以扩展到code外面一层的标签th,输入name="th",attrs={"scope":"row"}一样可以提取到支持的cms。
应用场景
心血来潮,想提取html里的一些内容
工具原理
没什么原理,直接套用的BeautifulSoup,我只是个搬运工!
更新日志
2018年5月23号上线,功能初成